Volodymyr Gubarkov

Experimenting with GC-less (heap-less) Java
February 2024 No LLM was used to write this article
What
https://github.com/xonixx/gc_less - in this repository I did a series of experiments in GC-less (heap-less) Java using sun.misc.Unsafe and also the newest alternative java.lang.foreign.MemorySegment.
GC-less (heap-less) means we allocate data structures in native memory directly (outside JVM heap). Such structures are not visible to GC. But this means that we are responsible for their (explicit) de-allocations (i.e., manual memory management).
Why
For fun and out of curiosity.
Basically it started when I wanted to check if the famous sun.misc.Unsafe approach is still viable with the latest Java.
Also, I wanted to try to program in Java like if I program in C and see how it goes.
How
sun.misc.Unsafe
It was a surprise to find that this class is still supported by the latest (at the time of this writing) Java version 23.
sun.misc.Unsafe class is unsafe indeed. You can easily crash your JVM with just a couple lines of code:
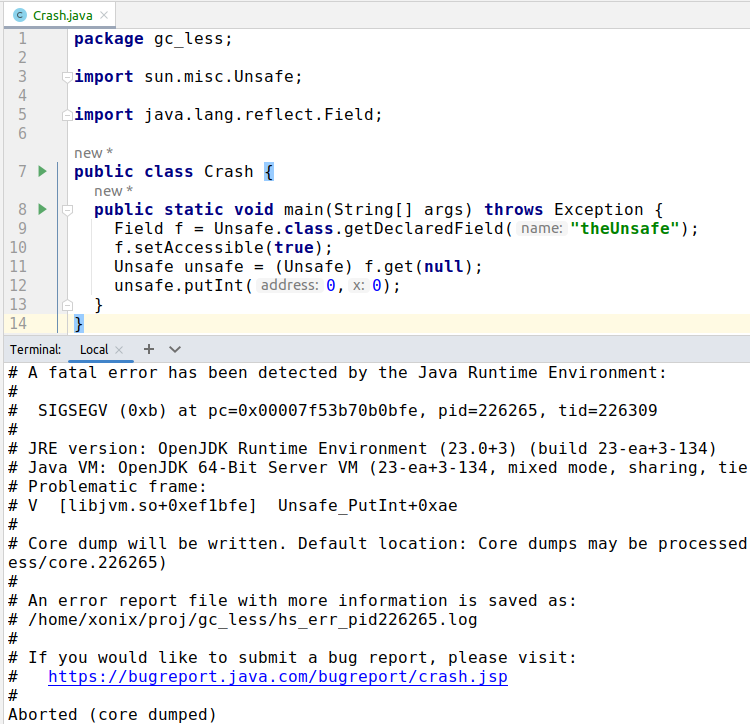
Yet still it appears to be pretty widely used.
Anyway, of interest to us is a family of methods in this class, related to off-heap memory management.
Data structures implementation
So as a practical application of GC-less (heap-less) style of programming I decided to implement some basic data structures:
- array
- array list
- stack
- hash table
Not only was I interested in how easy it is or if it’s feasible at all. I also wondered how the performance will compare to plain Java’s data structures.
Generating code by template
Instead of writing separate implementations for each Java type (int, long, double, etc.) I decided to generate them by templates.
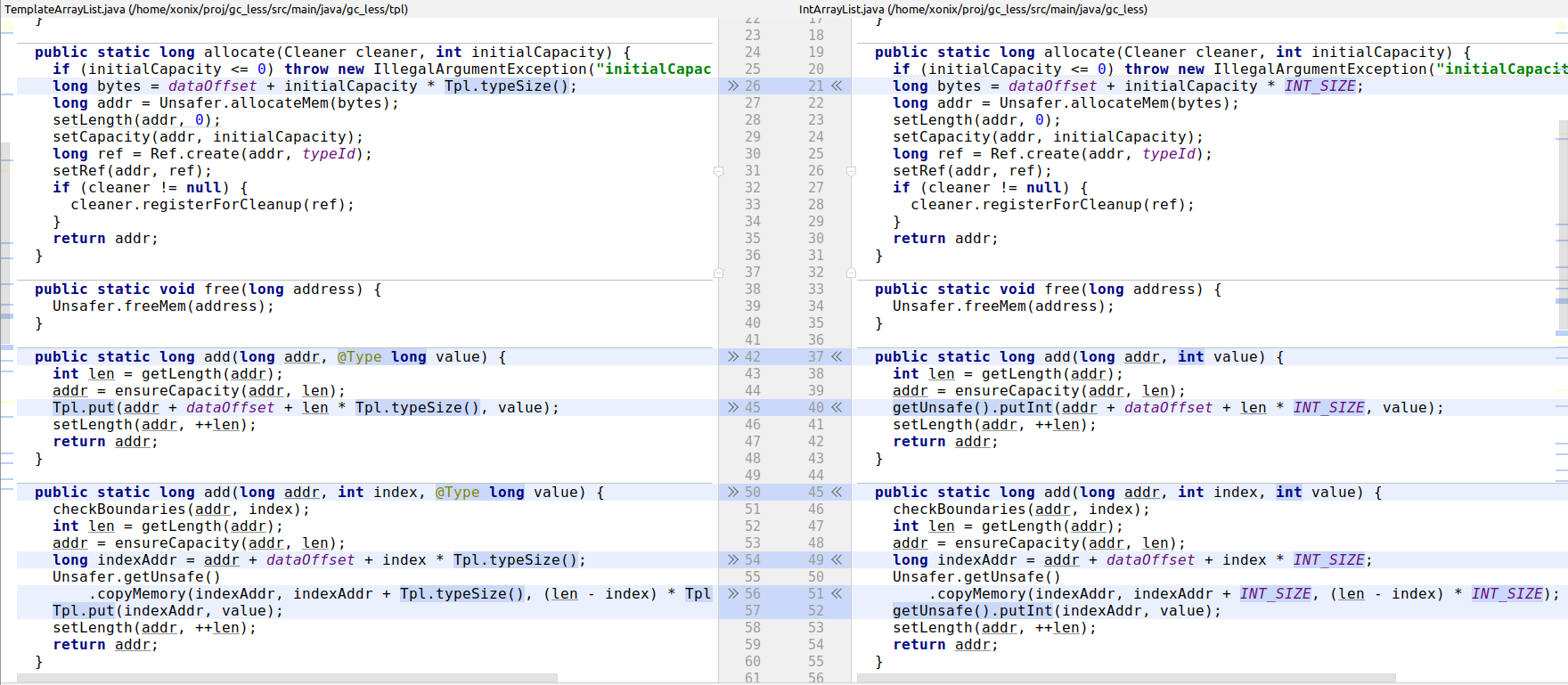
This way from a single template (for example, TemplateArrayList.java) the set on specialized implementations are generated:
Interesting to note is that the template itself is a runnable code. In fact implementation-wise it corresponds to long-specialized version.
This is convenient, because we can test a template and this makes sure all the specialized implementations are correct too.
The generation is implemented in form of a script gen.awk (Why AWK?).
We use annotation @Type and class Tpl to denote patterns to be replaced by a generator:
Epsilon GC
To make sure that we indeed do not (accidentally) consume heap I enabled the Epsilon GC setting.
Epsilon GC is “a GC that handles memory allocation but does not implement any actual memory reclamation mechanism. Once the available Java heap is exhausted, the JVM will shut down.”
Some implementation details
I implemented the data structures in a slightly “strange” OOP-resembling way.
So, for example, take a look at IntArrayList.
All the methods of this class are static, because we don’t want to allocate object on heap.
Also, all the methods (except for allocate, which plays a role of the constructor) accept long address as first parameter. It plays a role of this (in a sense, it is somehow analogous to Python’s self parameter).
So the usage looks like:
long address = IntArray.allocate(cleaner,10);
IntArray.set(address, 7, 222);
System.out.println(IntArray.get(address, 7));
So this long address plays a role of a reference. Obviously, with this you can’t have inheritance / overriding, but we don’t need it.
try-with-resources + Cleaner and Ref classes
The idea of the Cleaner class is you pass the instance of it in the allocation procedure of a (GC-less) class, such that the Cleaner becomes responsible for free-ing the memory of the allocated instance. This plays best with try-with-resources.
try (Cleaner cleaner = new Cleaner()) {
long array = IntArray.allocate(cleaner,10);
IntArray.set(array,1,1);
long map = IntHashtable.allocate(cleaner,10,.75f);
map = IntHashtable.put(map,1,1);
/*
Why do we re-assign the map?
It's because when the data structure grows,
it can eventually overgrow its initially-allocated memory region.
The algorithm will re-allocate the bigger internal storage which will cause
the address change.
*/
map = IntHashtable.put(map,2,22);
System.out.println(IntArray.getLength(array));
System.out.println(IntHashtable.getSize(map));
}
// both array and map above are de-allocated, memory reclaimed
Ref class is needed when we want to register some object for cleanup. But we can’t simply register its address, because the object can be relocated due to memory reallocation due to growing. So it means, the GC-less object registers for cleanup by Cleaner via the Ref and then the Ref pointer gets updated on each object relocation.
Memory leaks detection
I had an idea to implement memory leaks detection. This appeared relatively easy to achieve. The idea: on each memory allocation we remember the place (we instantiate new Exception() to capture a stack trace). On each corresponding memory free() we discard it.
Thus, at the end we check what’s left.
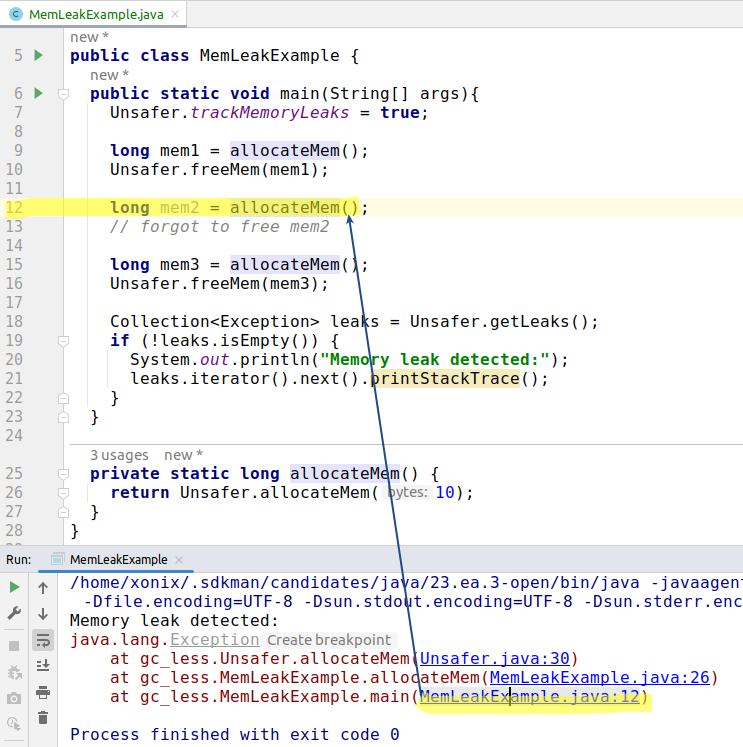
I implemented a base test class such that test that extends it can automatically ensure the absence of memory leaks.
Visual demonstration
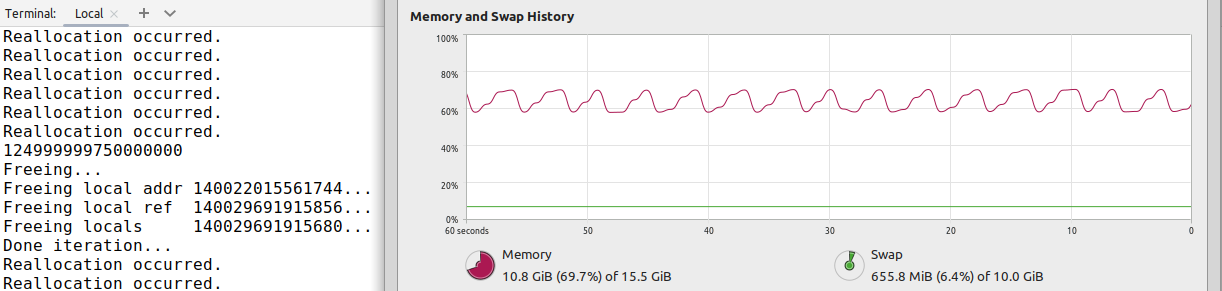
So we can say that one of the benefits of manual memory management off-heap is deterministic memory usage.
The class Main4 provides a visual demonstration of allocation and de-allocation in a loop as seen via memory graph of Task Manager:
java.lang.foreign.MemorySegment
It appears, that very recently this JEP emerged: “Deprecate Memory-Access Methods in sun.misc.Unsafe for Removal”.
This means that despite using memory-access methods in sun.misc.Unsafe is fun and sometimes useful, we can no longer rely on this functionality.
The JEP happens to provide the safer alternatives. I decided to take a deeper look at the updated API and understand how it compares to now deprecated sun.misc.Unsafe.
As an alternative we now have java.lang.foreign.MemorySegment class. It’s worth mentioning that this class is a part of a bigger API, dedicated to “invoking foreign functions (i.e., code outside the JVM)” that enables “Java programs to call native libraries and process native data without the brittleness and danger of JNI”.
Overall I found that the new API provides a “managed” API over the native memory. That is, when previously we accessed memory via long that represented the raw memory address, now we have java.lang.foreign.MemorySegment object (that represents both a pointer and a memory region).
This is, obviously, good. Using a dedicated get/set methods from that class gives much safer guarantees, like, for example, built-in out-of-bounds access checks, control of accessing properly aligned memory, etc.
It can seem that this API is much heavier. For every off-heap allocation we need to have an on-heap handle in the form of MemorySegment instance. So, we can think that this can render the idea of using the algorithms with lots of small allocations non-viable.
Surprisingly, this is not the case!
My sun.misc.Unsafe-based hashtable implementation is an example of an algorithm that uses many allocation. It’s a well-known hashtable algorithm (analogous to standard Java’s HashMap), with an array of buckets filled based on the hash code, and using linked lists of nodes for elements.
For the sake of experiment I converted it to MemorySegment. I was expecting that, because of many MemorySegment objects allocated, its JVM heap consumption will be proportional to the hashtable size.
Instead, experiment shows that the heap memory consumption is rather O(1).
How is this possible?
It appears that:
MemorySegmentis a value-based class as stated by its javadoc. Value-based classes represent the first move towards the inline classes that will be introduced by the project Valhalla.- It looks like the implementation of inlining value objects is already available at least for some JDK classes, like our
MemorySegment. This is implemented by excessive usage of@jdk.internal.vm.annotation.ForceInlineannotation: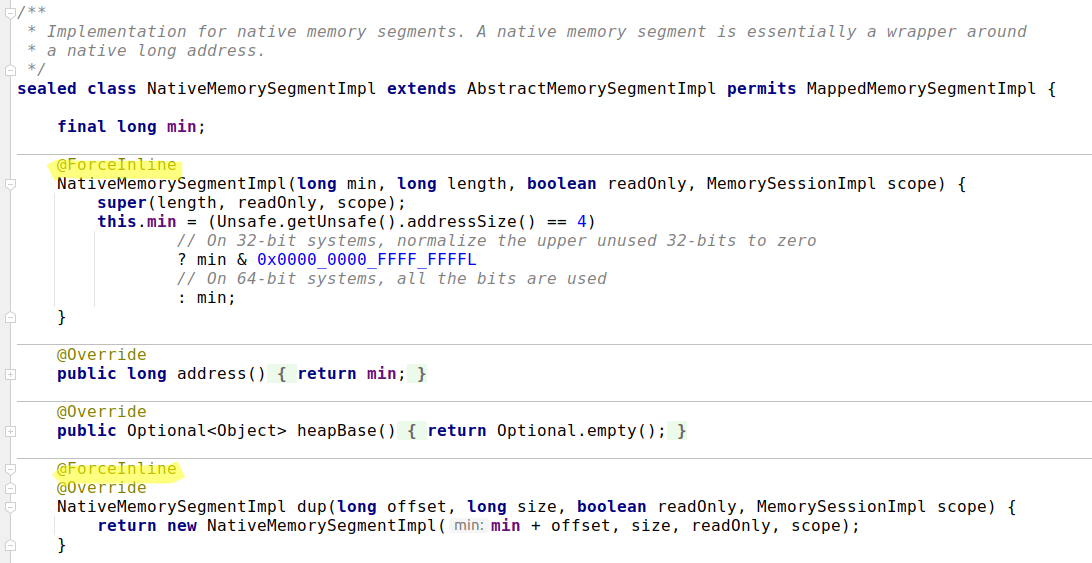
My take on this is that during the JIT-compilation all allocations of MemorySegments are completely removed by inlining this class.
Python-like hashtable implementation
While doing these experiments I was lucky enough to meet this article: Internals of sets and dicts. It describes the implementation details of sets and maps in the Python programming language.
It appears, that the dict (this is the name for hashtable in Python) algorithm in Python doesn’t use many allocations. Instead, it allocates one piece of memory and distributes the key, value, hashes data in it. When collection grows, it re-allocates this continuous piece of memory and re-distributes the data. This is exactly what we need!
So I came up with this MemorySegment-based, Python-based off-heap hashtable implementation.
Stress test with limited heap
With Java it’s inevitable, that even if you implement an off-heap algorithm, some heap will be used. So we can only consider an off-heap algorithm practical if it consumes small/fixed amount of heap. Otherwise, if its additional consumption of heap is proportional to the problem size, off-heap doesn’t make much sense.
I’ve created this small experiment - a program that allocates a hashtable and fills it with 50 million of elements for each of 3 implementation:
Unsafe-based hashtable- Python-based hashtable
MemorySegment-based hashtable
The experiment runs with Epsilon-GC with heap size fixed at 20 MB.
We can confirm that all three implementation pass the test with this heap limit.
[0.002s][info][gc] Using Epsilon
[0.003s][warning][gc,init] Consider enabling -XX:+AlwaysPreTouch to avoid memory commit hiccups
[0.011s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 1060K (5.18%) used
===== Unsafe-based hashtable =====
Unsafe-based: 0
Unsafe-based: 1000000
Unsafe-based: 2000000
Unsafe-based: 3000000
...
Unsafe-based: 47000000
Unsafe-based: 48000000
Unsafe-based: 49000000
Freeing...
Freeing local addr 140590889037840...
Freeing local ref 140596292148752...
Freeing locals 140596292147328...
===== MemorySegment-based hashtable =====
[16.869s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 2106K (10.28%) used
[16.941s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 3159K (15.43%) used
[16.980s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 4262K (20.82%) used
[17.019s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 5438K (26.55%) used
MemorySegment-based: 0
[17.084s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 6665K (32.55%) used
[17.129s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 7894K (38.55%) used
[17.165s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 9123K (44.55%) used
[17.186s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 10352K (50.55%) used
[17.203s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 11581K (56.55%) used
MemorySegment-based: 1000000
MemorySegment-based: 2000000
MemorySegment-based: 3000000
...
MemorySegment-based: 47000000
MemorySegment-based: 48000000
MemorySegment-based: 49000000
===== Python-based hashtable =====
Python-based: 0
Python-based: 1000000
Python-based: 2000000
Python-based: 3000000
...
Python-based: 47000000
Python-based: 48000000
Python-based: 49000000
[33.169s][info ][gc ] Heap: 20480K reserved, 20480K (100.00%) committed, 11993K (58.56%) used
Benchmarks
Finally, I would like to present to your attention couple benchmarks I’ve created.
AccessSpeedTest.java measures read/write speed (lower = better):
int[] |
Unsafe |
MemorySegment |
|
|---|---|---|---|
| Read test, ms | 1885 | 1883 | 1879 |
| Write test, ms | 2177 | 2213 | 2214 |
Surprisingly we can hardly see here any noticeable difference in speed, despite int[] and MemorySegment have bounds checking, so I expected them to be slower than Unsafe.
Another speed test is IntHashtableSpeedTest (lower = better):
| Implementation | Duration, ms |
|---|---|
Java’s HashMap |
40 |
| Unsafe-based | 130 |
| MemorySegment-based | 141 |
| Python-like | 5 |
| Python-like (MemorySegment) | 19 |
What can we see here?
- It appears that GC-less algorithms is generally slower than usual GC-full
- Built-in
HashMapis 3+ times faster thanUnsafe-based with similar algorithm - Python-like on-heap is almost 4 times faster than off-heap.
- Built-in
- It also appears that for the particular case of
map<int,int>it’s possible to come up with the implementation (Python-like) that is 8 times faster over the built-in implementation (HashMap)
Takeaways
- It is possible to use manual memory management in Java, for example, if you need deterministic memory consumption.
- Speed is not a good reason for using off-heap algorithms. We’ve seen that same algorithms are 3+ times slower off-heap. Probably due to better optimization opportunities for JIT compiler with usual Java code.
- In your implementation it’s advised to prefer
java.lang.foreign.MemorySegmentoversun.misc.Unsafe.
If you noticed a typo or have other feedback, please email me at xonixx@gmail.com