Volodymyr Gubarkov

A story about one refactoring of the parser grammar in IntelliJ-AWK
May 2023 No LLM was used to write this article
TL;DR
IntelliJ-AWK is a language support plugin for AWK that I develop for the IntelliJ IDEA.
I will describe how I tweaked the parsing grammar to solve one particular problem, and this also made it more resilient and allowed to remove some “code hacks”.
The article may be of interest to people developing a language support plugin for IntelliJ IDEA, or people interested in practical language parsing algorithms.
The story started with this issue. The autocomplete was not working in the presence of not-closed if:

Why so?
Let’s elaborate a bit. Autocompletion in IDE works by querying the nodes of the AST (abstract syntax tree) representation of a source code that is built by IDE behind the scene. To help you get the idea, the AST is conceptually similar to the DOM in HTML. It’s a tree-like structure that represents a parsed form of a program code. So, for example, to autocomplete the function names we need to traverse the AST tree and find all nodes of type "function".
Now, what does it take to turn the source code (text) into AST? It appears, that this is a two-step process:
- first is Lexer - it takes input source as string and produces a list of tokens
- second is Parser - it takes a list of tokens from Lexer and builds an AST
Why lexing and parsing should be separate?
Technically, lexing is usually implemented by auto-generating the Lexer algorithm code from a lexing grammar.
Likewise, Parser is usually auto-generated from a parsing grammar.
However, it’s also common to see manually written lexers and parsers.
It appears, that only lexing step is enough if all you need is to highlight the source code. You don’t need to build the full-fledged AST, you only need to know the actual tokens and color them in different colors by token type.
However, for any more advanced functionality, like aforementioned autocomplete, you need the AST.
But here is the problem. Usually, Parser can only build a complete and correct AST tree for complete and correct source code. However, when we are typing the program in IDE most of the time our source is incomplete. Thus, it’s simply invalid for the Parser.
Let’s see the actual example. Compare how the incomplete code is parsed (just linear list of tokens with the error at the end):
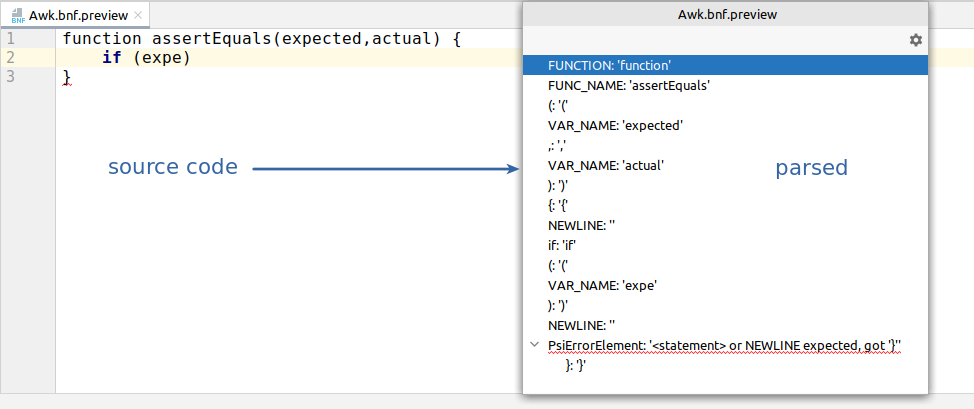
And how the complete code is parsed (AST tree is present):
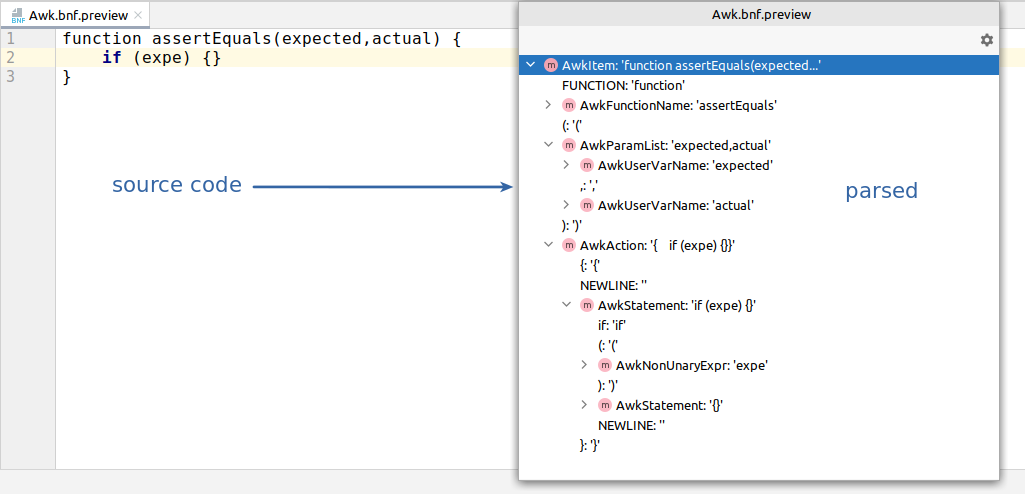
Grammar hints for recovery
In practice, it’s desirable for the IDE use-case to implement a parsing algorithm that is capable of building (at least partial) AST even in the presence of parsing errors. In other words, parser should be able to “recover” from the error and keep building syntax tree from subsequent tokens.
The parsing solution provided by IDEA, called Grammar-Kit, has means for this. It has two attributes that you can add to grammar rules to hint the parser on how to recover from parsing errors: pin and recoverWhile, described in docs (1, 2).
The key for our case is the pin one. You add it to a parsing rule by specifying the token index in a rule, after reaching which the parser will consider the rule match as successful, even if the rest of the tokens required for the rule is absent. It’s okay if this was completely incomprehensible. Let’s see on the same example.
Now I just added the { pin=1 } to the statement_if rule. Notice how now, even if there is a parse error, the AST tree is built.
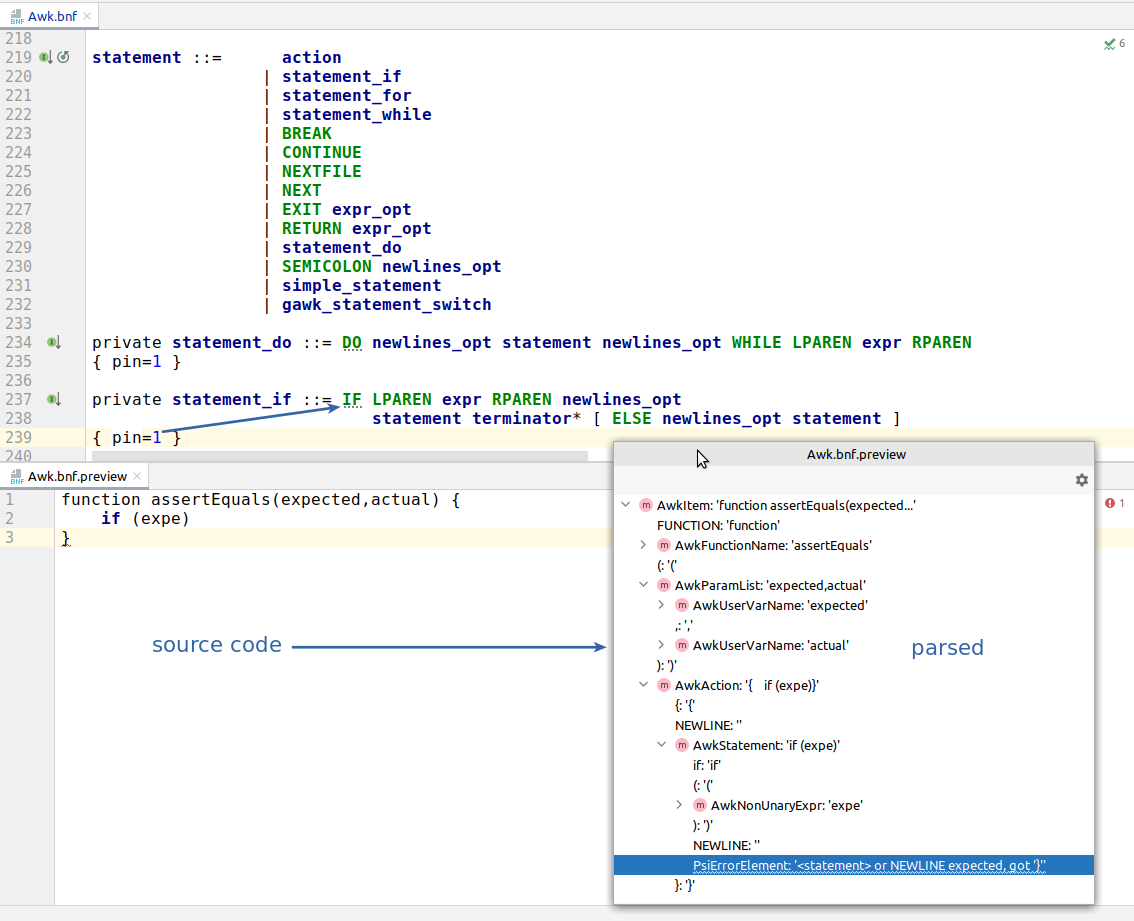
The error now is represented by the error AST leaf node at the end of “partially parsed” AST element (in this case, AwkStatement).
To someone who knows Prolog the behavior of pin will remind cuts (!).
Because it makes the parser to commit to the chosen parse choice once the specified token is reached, by canceling the backtracking for the rule with pin.
Also, to me the idea of pins has very clear logical sense. Once someone typed if (with space after it) it’s already clear this will be statement_if. User simply has no option to type something other than (condition) actions, since in all other inputs will be a syntax error. So it’s logical for the parser to assume statement_if AST element after seeing only the if token.
Also, I want to add one recommendation. Usually you want to set pin to the smallest value possible (that is 1). Remember, we use pin to help the parser to build the AST tree for more cases. So, for example, if you set { pin=2 } in our example with statement_if, it will only help to build an AST for { if ( } but not for { if }:

The tricky AWK grammar
If it were as simple as adding pin attributes to a grammar, I wouldn’t be writing this article.
In my AWK technical notes I’ve already mentioned, that due to a somewhat ad-hoc AWK syntax the language has a parsing grammar with some peculiarities, including even ambiguities.
The other such peculiarity can be observed in this excerpt from the grammar:
action : '{' newline_opt '}'
| '{' newline_opt terminated_statement_list '}'
| '{' newline_opt unterminated_statement_list '}'
;
terminator : terminator NEWLINE
| ';'
| NEWLINE
;
terminated_statement_list : terminated_statement
| terminated_statement_list terminated_statement
;
unterminated_statement_list : unterminated_statement
| terminated_statement_list unterminated_statement
;
terminated_statement : action newline_opt
| If '(' expr ')' newline_opt terminated_statement
| If '(' expr ')' newline_opt terminated_statement
Else newline_opt terminated_statement
| While '(' expr ')' newline_opt terminated_statement
| For '(' simple_statement_opt ';'
...
;
unterminated_statement : terminatable_statement
| If '(' expr ')' newline_opt unterminated_statement
| If '(' expr ')' newline_opt terminated_statement
Else newline_opt unterminated_statement
| While '(' expr ')' newline_opt unterminated_statement
| For '(' simple_statement_opt ';'
...
;
As you can see, there is some duplication here. Notably, you can see that if statement parsing happens in two rules: terminated_statement and unterminated_statement.
This duplication is needed because AWK (being terse language suited for one-liners) need to parse both terminated statement list (with statement terminator being \n or ';'):
{
print 1
print 2
}
and unterminated statement list:
{ print 1; print 2 }
In fact the only thing that tells the first from the second is the presence of terminator (newline or ';') before '}', so this is also terminated statement list:
{ print 1; print 2
}
the same as this:
{ print 1; print 2; }
Crazy, but this tiny detail needs this substantial duplication in the parser’s grammar.
Also, the performance of such parsing is questionable. Because it needs to try parsing terminated_statement_list first till the end (that is, till the closing '}'), and if the terminator is not there - backtrack and retry via the unterminated_statement_list parsing.
But what does this have to do with our problem? Remember, we want to add the pin attribute to the parsing of the if statement to facilitate an AST creation for the unfinished if.
Now, here is the problem. If we naively add pin to both terminated_statement_if and unterminated_statement_if we get broken parsing!
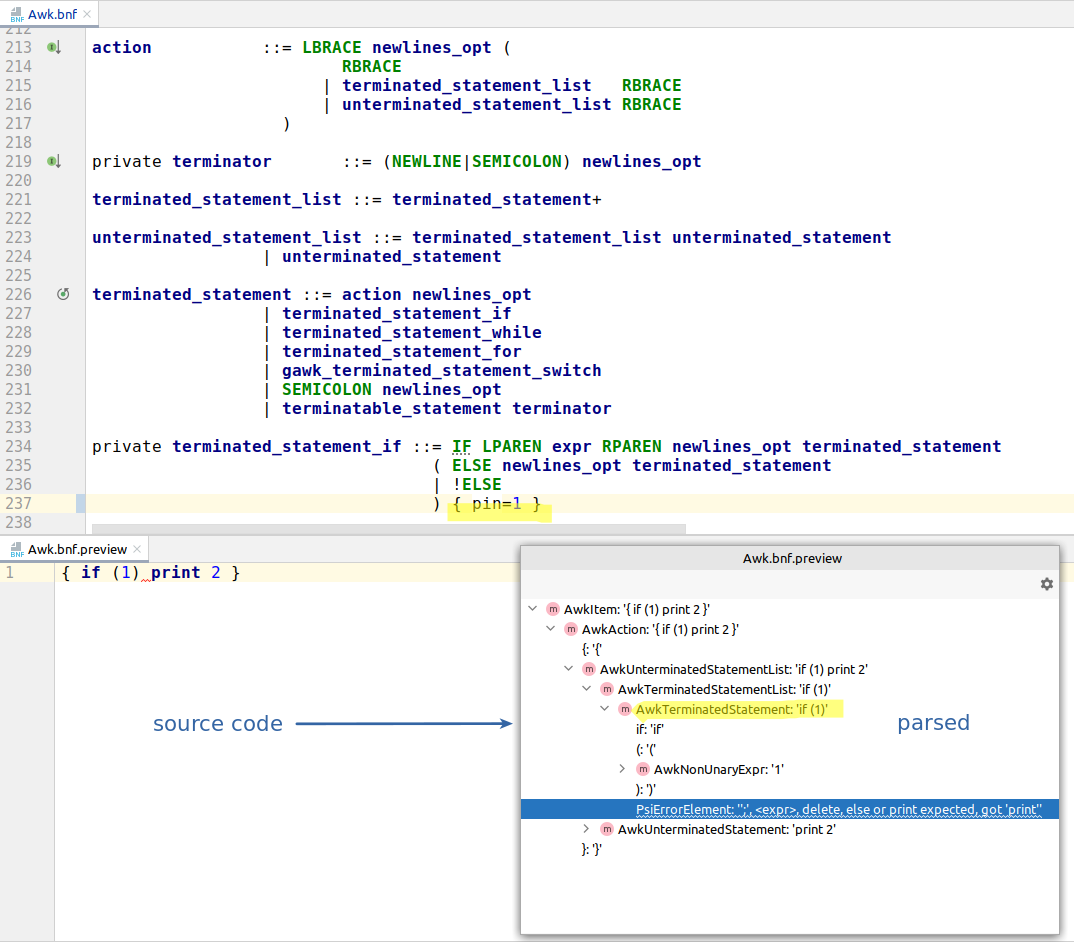
The reason for this is that pin makes the parsing always commit to terminated_statement_if (as the first in the order of parsing), even if it’s incomplete! Because this is the semantics of pin: it considers a rule match to be successful even for a partial match that reached “pinned” token.
Just in case, here is the correct parsing (that resolves to unterminated_statement_if):
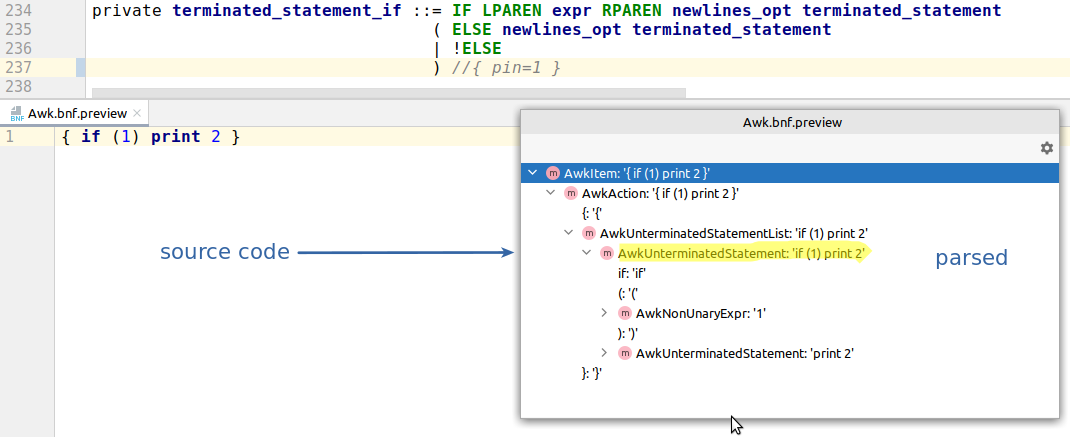
If you read my article carefully, at this point you might have a question. How come in the beginning I was adding pin for the same if case, and it was working?
I should apologize for some inconsistency in my story. The project IntelliJ-AWK was started by using the exact AWK grammar as provided by specification. In the first part of the article I was adding pin for the already rewritten parser grammar, where I was able to get rid of the aforementioned duplication ¯\_(ツ)_/¯
Though, once again, you may still ask. How come you got rid of grammar duplication with terminated and unterminated statements? Was it not necessary? You just have explained how exactly it was necessary.
Absolutely valid question!
The negative implication of such rewrite is that now the grammar is more permissive than it should be. This means it parses as valid some invalid programs!
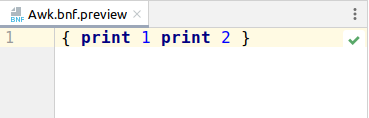
Is it an issue? Yes, but minor. Since the probability of writing this code is low and the problem will be immediately caught on the first run.
Result
Was it worth it? Absolutely!
Now, autocompletion works even in the presence of incomplete if (for, while, etc.) statement.
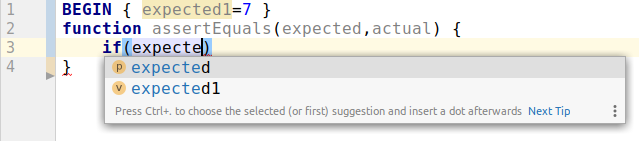
Besides, with this approach I was able to remove couple nasty hacks I had, like this one.
Sadly, I can’t confirm that the rewrite produced any noticeable parsing speed-up. Here is the measurements:
| Before | After | |
|---|---|---|
| Tests count | 1053 | 1069 |
| Tests execution time | 48 sec | 47 sec |
Although, it looks like a slight speedup, but also can be just a fluctuation.
The described change was delivered as part of version 0.4.0 of the plugin.
Future plans
Add even more grammar parsing hints to cover even more cases for error recovery.
Also, I have a feeling that it should be possible to re-introduce the lost restrictiveness of the grammar while preserving the achieved parsing resilience.
Also, it appears, that standardized AWK grammar, when converted to IDEA’s Grammar-Kit, doesn’t properly handle operators priority. This needs to be addressed.
If you noticed a typo or have other feedback, please email me at xonixx@gmail.com